XCTF-RE进阶区部分实现(持续更新)
写在前面的话 还是决定把进阶区以前写过也都记录一下,也算是一个温故知新的过程吧。另外希望自己能早点把进阶区百人以上的题目刷完,加油!(2020.6.2)。
啊,进阶区的题目经常会有变动,前面的题可能会被调到后面,所以顺序可能会不太对。
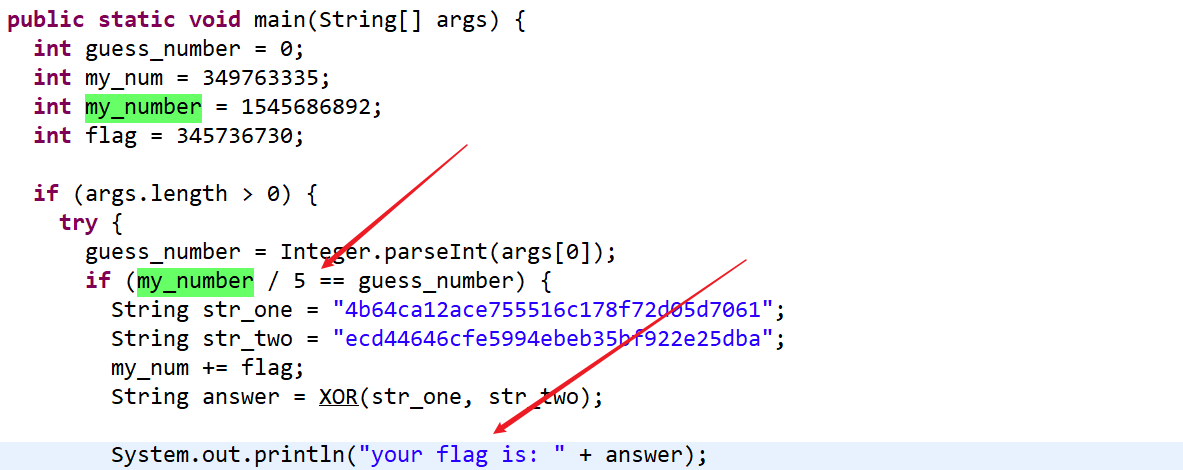
Guess-the-Number 拿到程序,是个jar文件,拖进jd-jui查看,可以直接看到主函数。可以看到,当判断成立时,经过异或运算后会直接输出flag
my_number 的数值已经直接给出了,直接运算向下取整 作为输入
或者也可以按照程序给的数值直接运算出flag ,这个代码我目前实在不会写,直接照着别人的代码写的,等有自己的理解的再来更
1 2 3 4 5 6 7 8 9 a = '4b64ca12ace755516c178f72d05d7061' b = 'ecd44646cfe5994ebeb35bf922e25dba' c = bytes .fromhex(a) d = bytes .fromhex(b) flag = [0 ] * 16 for i in range (len (c)): flag[i] = c[i] ^ d[i] flag[i] = hex (flag[i]) print (flag)
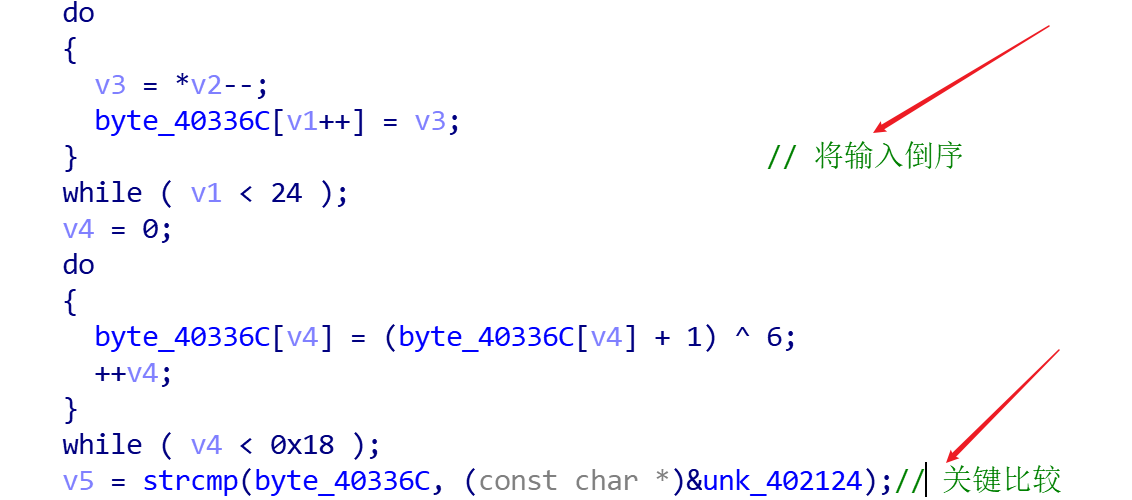
EasyRE 直接搜字符串发现有个flag,提交发现是错的,然后对字符串right一路交叉引用过去找到主要判断函数
注意一下输入是倒序就行,然后这个题的反汇编是有一定错误的,v2指向不明,不过不影响做题,因为好猜,读一下发现不难理解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 .text:00401100 loc_401100: ; CODE XREF: sub_401080+8E↓j .text:00401100 mov al, [esi] .text:00401102 lea esi, [esi-1] .text:00401105 mov byte_40336C[edx], al .text:0040110B inc edx .text:0040110C cmp edx, ecx .text:0040110E jl short loc_401100 .text:00401110 pop esi .text:00401111 .text:00401111 loc_401111: ; CODE XREF: sub_401080+6F↑j .text:00401111 xor edx, edx .text:00401113 .text:00401113 loc_401113: ; CODE XREF: sub_401080+A6↓j .text:00401113 mov al, byte_40336C[edx] .text:00401119 inc al .text:0040111B xor al, 6 .text:0040111D mov byte_40336C[edx], al .text:00401123 inc edx .text:00401124 cmp edx, ecx .text:00401126 jb short loc_401113 .text:00401128 mov ecx, offset unk_402124 .text:0040112D mov eax, offset byte_40336C .text:00401132
直接上代码:
1 2 3 4 5 6 7 cm = [0x78 , 0x49 , 0x72 , 0x43 , 0x6A , 0x7E , 0x3C , 0x72 , 0x7C , 0x32 , 0x74 , 0x57 , 0x73 , 0x76 , 0x33 , 0x50 , 0x74 , 0x49 , 0x7F , 0x7A , 0x6E , 0x64 , 0x6B , 0x61 ] flag = '' for i in range (len (cm)): flag += chr ((cm[i] ^ 6 ) - 1 ) print (flag[::-1 ])
Shuffle 签到水瓶,根据题目描述,可知主函数给出的一长列字符就是要找到flag
1 2 3 4 5 cm = [83 ,69 ,67 ,67 ,79 ,78 ,123 ,87 ,101 ,108 ,99 ,111 ,109 ,101 ,32 ,116 ,111 ,32 ,116 ,104 ,101 ,32 ,83 ,69 ,67 ,67 ,79 ,78 ,32 ,50 ,48 ,49 ,52 ,32 ,67 ,84 ,70 ,33 ,125 ] flag = '' for i in range (len (cm)): flag += chr (cm[i]) print (flag)
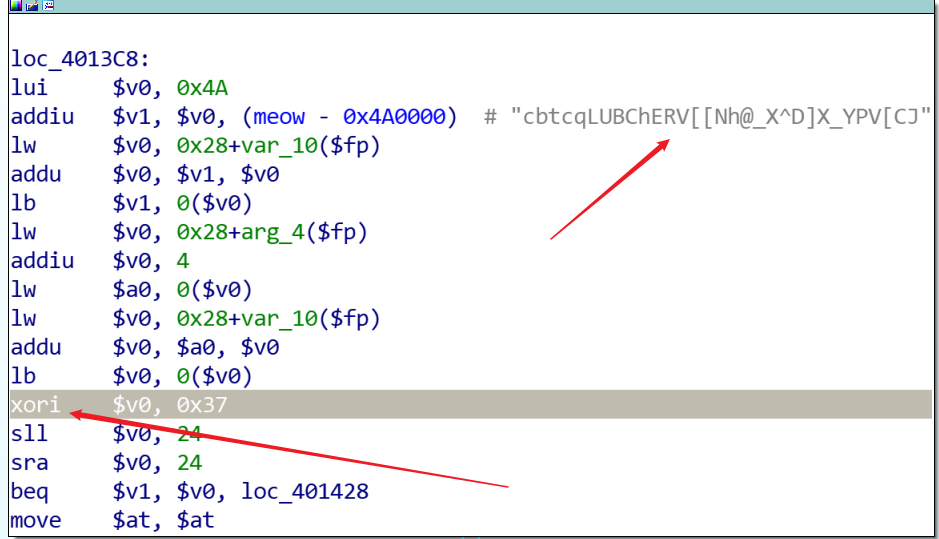
re-for-50-plz-50 打开发现无法反编译MIPS,可以考虑A:去官网下载插件,或者B:直接读汇编。但是这里我选C,我赌出题人的枪里没有子弹。
1 2 3 4 5 cm = 'cbtcqLUBChERV[[Nh@_X^D]X_YPV[CJ' flag = '' for i in range (len (cm)): flag += chr (ord (cm[i]) ^ 0x37 ) print (flag)
dmd-50 一开始我以为又是直接硬塞flag,把数字转成字符就OK了,但验证发现并不对
然后仔细看了下主函数,发现有一部把输入进行MD5加密的过程,所以需要解MD5,直接在线解就可以了
parallel-comparator-200 给的是c代码,从结果进行反推
首先is_ok必须为1,那么下图两个字符串必须相等
1 2 3 4 5 6 int is_ok = 1 ;for (i = 0 ; i < FLAG_LEN; i++) { if (generated_string[i] != just_a_string[i]) return 0 ; } return 1 ;
要想相等则result必须为0
1 2 3 4 5 6 for (i = 0 ; i < FLAG_LEN; i++) { pthread_join(*(thread+i), &result); generated_string[i] = *(char *)result + just_a_string[i]; free (result); free (arguments[i]); }
则checking函数反回为0
1 2 3 4 5 6 7 8 9 char *arguments[20 ];for (i = 0 ; i < FLAG_LEN; i++) { arguments[i] = (char *)malloc (3 *sizeof (char )); arguments[i][0 ] = first_letter; arguments[i][1 ] = differences[i]; arguments[i][2 ] = user_string[i]; pthread_create((pthread_t *)(thread+i), NULL , checking, arguments[i]); }
则**(argument[0]+argument[1])与argument[2]必须相同**
1 2 3 4 5 6 void * checking (void *arg) { char *result = malloc (sizeof (char )); char *argument = (char *)arg; *result = (argument[0 ]+argument[1 ]) ^ argument[2 ]; return result; }
然后我们知道arg[0]是产生的随机数,范围在97到97+26之间,开始爆破
1 2 3 4 5 6 a = [0 , 9 , -9 , -1 , 13 , -13 , -4 , -11 , -9 , -1 , -7 , 6 , -13 , 13 , 3 , 9 , -13 , -11 , 6 , -7 ] for i in range (97 ,123 ): flag = '' for j in range (len (a)): flag += chr (i + a[j]) print (flag)
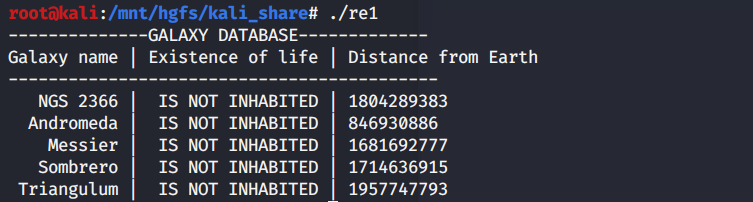
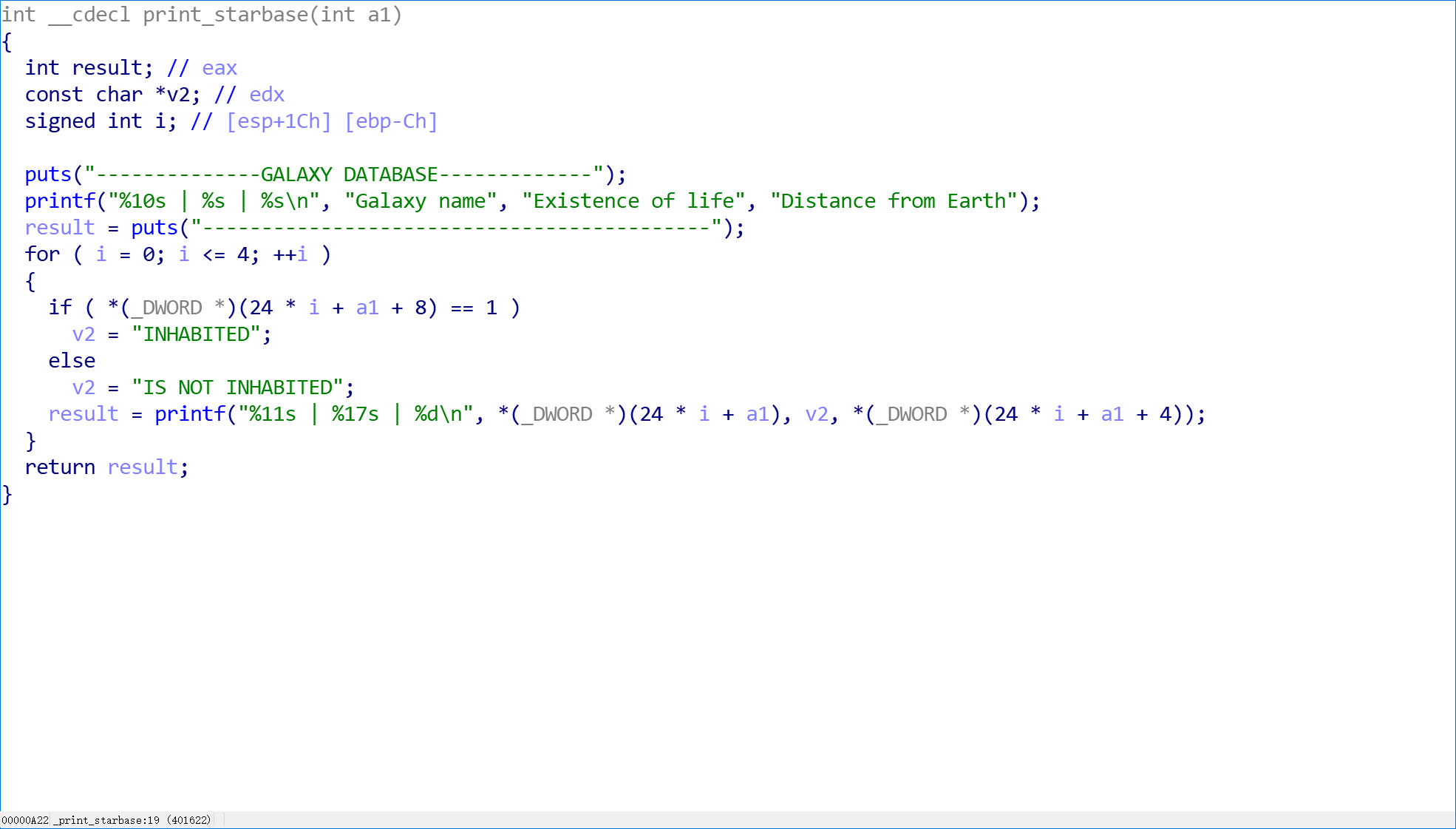
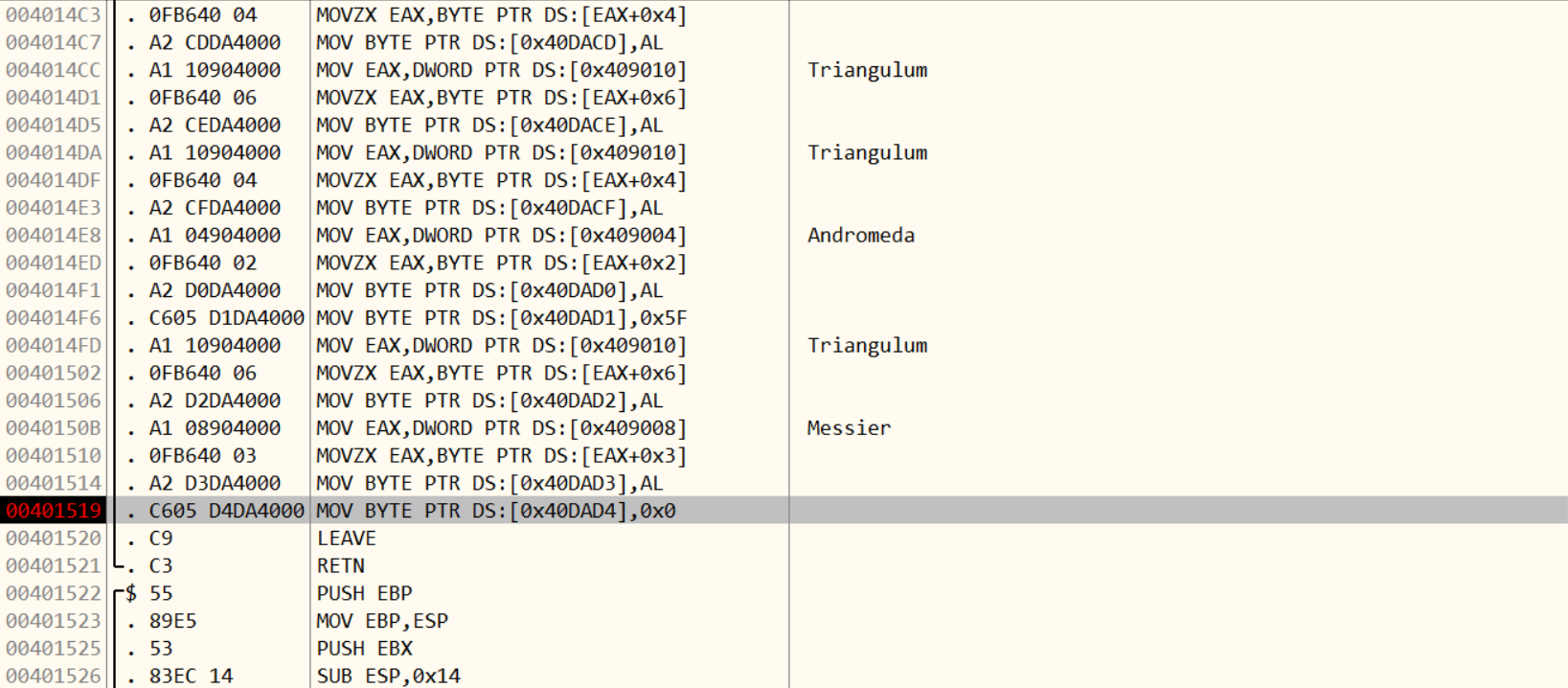
secret-galaxy-300 文件夹里三个文件,exe跑一下发现闪退,kali下跑如下图
给的这也不知道是啥,IDA查看一下,对应上图可以看出输出逻辑,但好像并没有什么用
好的没思路这个时候是时候shift+f12走一波了
发现了一个存在但是没有输出显示的黑色神秘星系,然后一路交叉引用
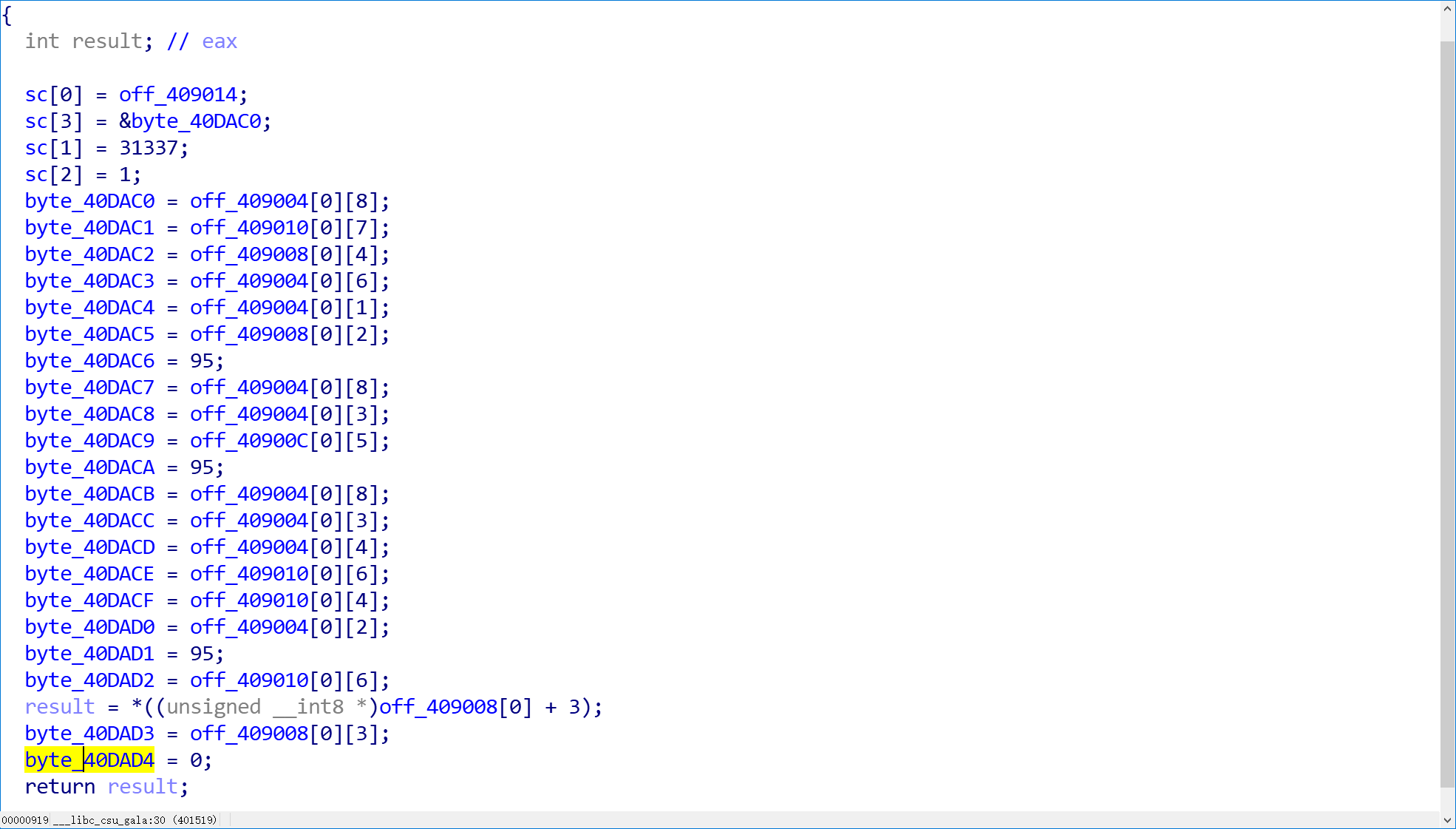
好家伙,都是赋值操作,建议彻查,这里记录下结尾处的地址,然后去OD中调试
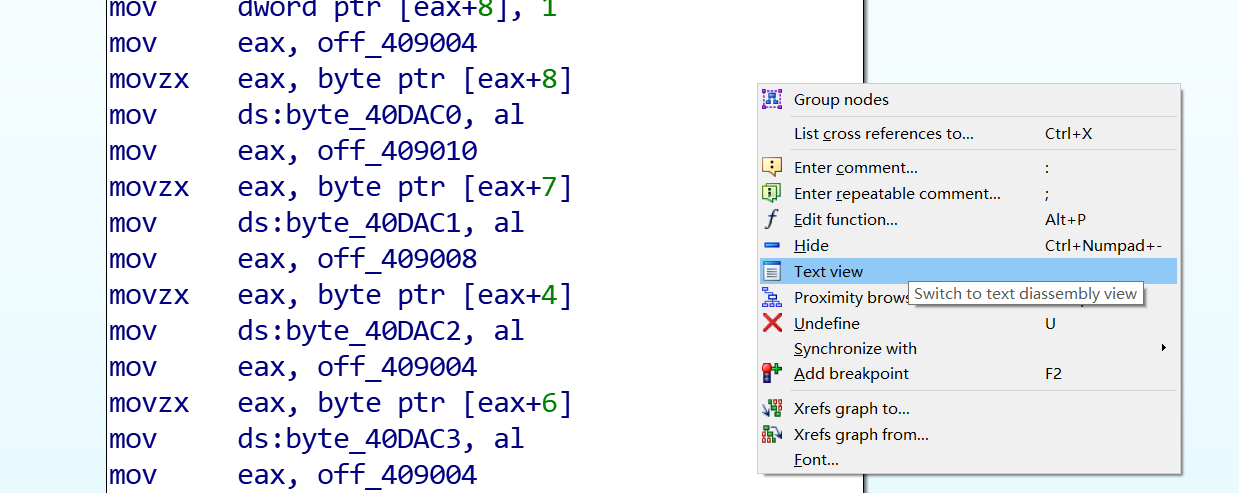
这里额外说一下(因为当初这个问题困扰了我),如何快速查看地址,如下图进入text view就OK了
选中,右键-在数据窗口中跟随-内存地址,然后运行
字符串直接提交即可。
其实挺简单一个题,但刚开始自己没想到,一通胡乱分析猛如虎,之后然后看了题解才明白,捞的不谈。
srm-50 直接进入winmain 函数,有一些套话废话看不懂问题不大,直接分析主要矛盾就OK。
使之判断成功就行,注意V11的定义。
Mysterious 这道题刚开始我错误的理解了atoi 和itoa 导致纠结了不少时间,建议仔细读一下函数说明。然后注意这个string给的定义是char
主要注意事项如下图:
re1-100 大体流程:程序把输入先进行一系列判断,然后将输入打乱顺序后和给定的字符串进行比较,一些对解题没用的if语句可以选择性跳过,详见注释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 int __cdecl __noreturn main (int argc, const char **argv, const char **envp) { __pid_t v3; size_t v4; ssize_t v5; bool v6; bool bCheckPtrace; ssize_t numRead; ssize_t numReada; char bufWrite[200 ]; char bufParentRead[200 ]; unsigned __int64 v12; v12 = __readfsqword(0x28 u); bCheckPtrace = detectDebugging(); if ( pipe(pParentWrite) == -1 ) exit (1 ); if ( pipe(pParentRead) == -1 ) exit (1 ); v3 = fork(); if ( v3 != -1 ) { if ( v3 ) { close(pParentWrite[0 ]); close(pParentRead[1 ]); while ( 1 ) { printf ("Input key : " ); memset (bufWrite, 0 , 0xC8 uLL); gets(bufWrite); v4 = strlen (bufWrite); v5 = write(pParentWrite[1 ], bufWrite, v4); if ( v5 != strlen (bufWrite) ) printf ("parent - partial/failed write" ); do { memset (bufParentRead, 0 , 0xC8 uLL); numReada = read(pParentRead[0 ], bufParentRead, 0xC8 uLL); v6 = bCheckPtrace || checkDebuggerProcessRunning(); if ( v6 ) { puts ("Wrong !!!\n" ); } else if ( !checkStringIsNumber(bufParentRead) ) { puts ("Wrong !!!\n" ); } else { if ( atoi(bufParentRead) ) { puts ("True" ); if ( close(pParentWrite[1 ]) == -1 ) exit (1 ); exit (0 ); } puts ("Wrong !!!\n" ); } } while ( numReada == -1 ); } } close(pParentWrite[1 ]); close(pParentRead[0 ]); while ( 1 ) { memset (bufParentRead, 0 , 0xC8 uLL); numRead = read(pParentWrite[0 ], bufParentRead, 0xC8 uLL); if ( numRead == -1 ) break ; if ( numRead ) { if ( childCheckDebugResult() ) { responseFalse(); } else if ( bufParentRead[0 ] == '{' ) { if ( strlen (bufParentRead) == 42 ) { if ( !strncmp (&bufParentRead[1 ], "53fc275d81" , 0xA uLL) ) { if ( bufParentRead[strlen (bufParentRead) - 1 ] == '}' ) { if ( !strncmp (&bufParentRead[31 ], "4938ae4efd" , 0xA uLL) ) { if ( !confuseKey(bufParentRead, 42 ) ) { responseFalse(); } else if ( !strncmp (bufParentRead, "{daf29f59034938ae4efd53fc275d81053ed5be8c}" , 0x2A uLL) ) { responseTrue(); } else { responseFalse(); } } else { responseFalse(); } } else { responseFalse(); } } else { responseFalse(); } } else { responseFalse(); } } else { responseFalse(); } } } exit (1 ); } exit (1 ); }
关键key混淆函数:
1 2 3 4 5 6 7 8 9 10 11 strncpy (szPart1, szKey + 1 , 0xA uLL); strncpy (szPart2, szKey + 11 , 0xA uLL);strncpy (szPart3, szKey + 21 , 0xA uLL);strncpy (szPart4, szKey + 31 , 0xA uLL);memset (szKey, 0 , 0x2A uLL);*szKey = '{' ; strcat (szKey, szPart3); strcat (szKey, szPart4);strcat (szKey, szPart1);strcat (szKey, szPart2);szKey[41 ] = '}' ;
answer_to_everything 直接看程序
1 2 3 printf ("Gimme: " , argv, envp);__isoc99_scanf((__int64)"%d" , (__int64)&v4); not_the_flag(v4);
not_the_flag
1 2 3 4 if ( a1 == 42 ) puts ("Cipher from Bill \nSubmit without any tags\n#kdudpeh" ); else puts ("YOUSUCK" );
如果输入为42,就会输出来自bill的密码,又说不要任何标签,所以判断密码就是kdudpeh ,然后提交会发现错误,这个时候就体现读题的重要性了,来自sha1的密码,OK,sha1加密
加密脚本(也可选择在线加密):
1 2 3 4 import hashliba='kdudpeh' b=hashlib.sha1(a.encode('utf-8' )) print (b.hexdigest())
elrond32 先说题目大概思路,先一个if判断,成功就输出**”Access granted”**,同时执行puts下面的函数。
进入sub_8048414 函数,程序还是很简单的,直接手撕,得到a2:isengard
继续分析,进入sub_8048538 ,函数的参数用到了上面我们刚得到的a2,大体上这是一个输出过程,猜测输出的就是flag,那对unk_8048760 里的数据进行数据提取,然后进行简单的异或后应该
数据提取:IDA里选中数据按shift+e可以进行数据提取 ,提取的数据有无用的部分,需要进行再提取,比如int四个字节那每四个取第一个就OK,脚本如下(因为python学艺不精,所以用的c++)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <iostream> #include <cstring> using namespace std;int main () int a[] = { 0x0F , 0x00 , 0x00 , 0x00 , 0x1F , 0x00 , 0x00 , 0x00 , 0x04 , 0x00 , 0x00 , 0x00 , 0x09 , 0x00 , 0x00 , 0x00 , 0x1C , 0x00 , 0x00 , 0x00 , 0x12 , 0x00 , 0x00 , 0x00 , 0x42 , 0x00 , 0x00 , 0x00 , 0x09 , 0x00 , 0x00 , 0x00 , 0x0C , 0x00 , 0x00 , 0x00 , 0x44 , 0x00 , 0x00 , 0x00 , 0x0D , 0x00 , 0x00 , 0x00 , 0x07 , 0x00 , 0x00 , 0x00 , 0x09 , 0x00 , 0x00 , 0x00 , 0x06 , 0x00 , 0x00 , 0x00 , 0x2D , 0x00 , 0x00 , 0x00 , 0x37 , 0x00 , 0x00 , 0x00 , 0x59 , 0x00 , 0x00 , 0x00 , 0x1E , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 , 0x59 , 0x00 , 0x00 , 0x00 , 0x0F , 0x00 , 0x00 , 0x00 , 0x08 , 0x00 , 0x00 , 0x00 , 0x1C , 0x00 , 0x00 , 0x00 , 0x23 , 0x00 , 0x00 , 0x00 , 0x36 , 0x00 , 0x00 , 0x00 , 0x07 , 0x00 , 0x00 , 0x00 , 0x55 , 0x00 , 0x00 , 0x00 , 0x02 , 0x00 , 0x00 , 0x00 , 0x0C , 0x00 , 0x00 , 0x00 , 0x08 , 0x00 , 0x00 , 0x00 , 0x41 , 0x00 , 0x00 , 0x00 , 0x0A , 0x00 , 0x00 , 0x00 , 0x14 , 0x00 , 0x00 , 0x00 }; int j = 0 ; int x = sizeof (a)/16 ; int b[x]; cout<<"length is:" <<x<<endl; for (int i =0 ;i<sizeof (a)/4 ;i++) { if (i%4 ==0 ) { b[j++] = a[i]; } } for (int c = 0 ;c<sizeof (b)/4 ;c++){ cout<<b[c]<<',' ; } return 0 ; }
提取到了数据,开始写flag脚本
1 2 3 4 5 6 a = [105 ,115 ,101 ,110 ,103 ,97 ,114 ,100 ] b = [15 ,31 ,4 ,9 ,28 ,18 ,66 ,9 ,12 ,68 ,13 ,7 ,9 ,6 ,45 ,55 ,89 ,30 ,0 ,89 ,15 ,8 ,28 ,35 ,54 ,7 ,85 ,2 ,12 ,8 ,65 ,10 ,20 ] flag = '' for i in range (len (b)): flag += chr (b[i] ^ a[i % 8 ]) print (flag)
或者更简单的方法是,既然判断成功就会输出,并且我们已经知道输入了,那直接在kali中运行
tt3441810 这题说是逆向确实有些勉强了,但是了解到了一点xxd指令 (皮毛)
首先用exeinfope或者file指令查看文件类型:ASCII text, with CRLF line terminators
拖进sublime查看一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 00400080 68 66 6C 00 00 48 BF 01 00 00 00 00 00 00 00 48 00400090 8D 34 24 48 BA 02 00 00 00 00 00 00 00 48 B8 01 004000A0 00 00 00 00 00 00 00 0F 05 68 61 67 00 00 48 BF 004000B0 01 00 00 00 00 00 00 00 48 8D 34 24 48 BA 02 00 004000C0 00 00 00 00 00 00 48 B8 01 00 00 00 00 00 00 00 004000D0 0F 05 68 7B 70 00 00 48 BF 01 00 00 00 00 00 00 004000E0 00 48 8D 34 24 48 BA 02 00 00 00 00 00 00 00 48 004000F0 B8 01 00 00 00 00 00 00 00 0F 05 68 6F 70 00 00 00400100 48 BF 01 00 00 00 00 00 00 00 48 8D 34 24 48 BA 00400110 02 00 00 00 00 00 00 00 48 B8 01 00 00 00 00 00 00400120 00 00 0F 05 68 70 6F 00 00 48 BF 01 00 00 00 00 00400130 00 00 00 48 8D 34 24 48 BA 02 00 00 00 00 00 00 00400140 00 48 B8 01 00 00 00 00 00 00 00 0F 05 68 70 72 00400150 00 00 48 BF 01 00 00 00 00 00 00 00 48 8D 34 24 00400160 48 BA 02 00 00 00 00 00 00 00 48 B8 01 00 00 00 00400170 00 00 00 00 0F 05 68 65 74 00 00 48 BF 01 00 00 00400180 00 00 00 00 00 48 8D 34 24 48 BA 02 00 00 00 00 00400190 00 00 00 48 B8 01 00 00 00 00 00 00 00 0F 05 68 004001A0 7D 0A 00 00 48 BF 01 00 00 00 00 00 00 00 48 8D 004001B0 34 24 48 BA 02 00 00 00 00 00 00 00 48 B8 01 00 004001C0 00 00 00 00 00 00 0F 05 48 31 FF 48 B8 3C 00 00 004001D0 00 00 00 00 00 0F 05
这里可以写脚本把16进制转为ASCII码,这里介绍学到的用xxd指令转换
关于xxd指令的内容,我没有找到一篇说写的很好的,这里放两篇勉强能冲的:
1.https://www.sohu.com/a/341144249_610671
2.https://blog.csdn.net/xingyyn78/article/details/79438853
到这里可以直接进行分析了,规律还是很明显的,或者嫌看着难受可以先选出可打印字符:
1 2 3 4 5 6 a = "@�hflH�H@��4$H�H�@�hagH�@�H�4$H�@�H�@�h{pH�@�H�4$H�H@��hop@H�H�4$H�@H�@ hpoH�@0H�4$H�@@H�hpr@PH�H�4$@`H�H�@phetH�@�H�4$H�@�H�h@�}H�H�@�4$H�H�@�H1�H�<@� " flag = '' for i in range (len (a)): if (ord (a[i]) >= 32 and ord (a[i]) <= 125 ): flag += a[i] print (flag)
得到字符串:
1 @hflHH@4$HH@hagH@H4$H@H@h{pH@H4$HH@hop@HH4$H@H@ hpoH@0H4$H@@Hhpr@PHH4$@`HH@phetH@H4$H@Hh@}HH@4$HH@H1H<@
很明显可以观察到我们需要的是h后面H之前(有时是@)的字符
得到flag:
然后交了很多次发现不对,去掉flag{}即可
这里额外介绍一个一条指令秒的题解,连接https://github.com/ctfs/write-ups-2014/tree/master/tinyctf-2014/tt3441810
流浪者 交叉引用字符串pass!找到关键函数,函数逻辑是对输入的字符按ascii码值进行变换,变换后的结果作为字符串abcd……XYZ的索引。
脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 a = 'abcdefghiABCDEFGHIJKLMNjklmn0123456789opqrstuvwxyzOPQRSTUVWXYZ' b = 'KanXueCTF2019JustForhappy' print (len (b))print (len (a))f = [] for i in range (len (b)): for j in range (len (a)): if (a[j] == b[i]): f.append(j) for i in range (len (f)): if (f[i]>=10 and f[i] <= 35 ): f[i] += 87 elif (f[i]>=0 and f[i] <= 9 ): f[i] += 48 elif (f[i]>=36 and f[i] <= 61 ): f[i] += 29 flag = '' for i in range (len (f)): flag += chr (f[i]) print (flag)
写脚本的时候我犯了个错,在连续判断的if语句那,我第一次没有用elif 而是连用了三个if ,这样的后果就是进行第一个if判断后,修>改后的值可能会满足剩下的if判断条件,造成多次判断成功的情况,当时一直没发现,这里感谢好兄弟ld1ng 的指正。
666 一觉起来打开一看,首页莫名其妙又多了个没写的,本来不想写的,强迫症,没办法
逻辑倒是简单,直接上脚本
1 2 3 4 5 6 7 8 9 10 11 12 key = 0x12 flag = '' cmpa = [0x69 , 0x7A , 0x77 , 0x68 , 0x72 , 0x6F , 0x7A , 0x22 , 0x22 , 0x77 , 0x22 , 0x76 , 0x2E , 0x4B , 0x22 , 0x2E , 0x4E , 0x69 ]for i in range (0 ,6 ): x = chr ((cmpa[3 * i] ^ key) - 6 ) y = chr ((cmpa[3 * i + 1 ] ^ key) + 6 ) z = chr ((cmpa[3 * i + 2 ] ^ key) ^ 6 ) flag += x flag += y flag += z print (flag)
这里注意到异或的优先级,我刚开始没加上括号,然后结果不对,之后我才意识到异或的优先级好像比减和加要低。
Windows_Reverse1 这里先感谢两位师傅ld1ng 和iyzyi 对我写这道题提供的帮助,有你们真好:smiley:。
这个题让我很疑惑看不懂的地方就在于其独特的参数表示方式,闻所未闻(主要是孤陋寡闻)。
首先这个题是有壳的,不过upx-d可以直接脱,但是脱壳之后的程序运行就闪退,原因是程序开启了ASLR ,但是使用的确实绝对地址,所以把ASLR关掉之后就可以了。这里我也是借鉴的网上大佬的博客,链接:
https://blog.csdn.net/qq_43547885/article/details/104412656
以及http://blog.eonew.cn/archives/749
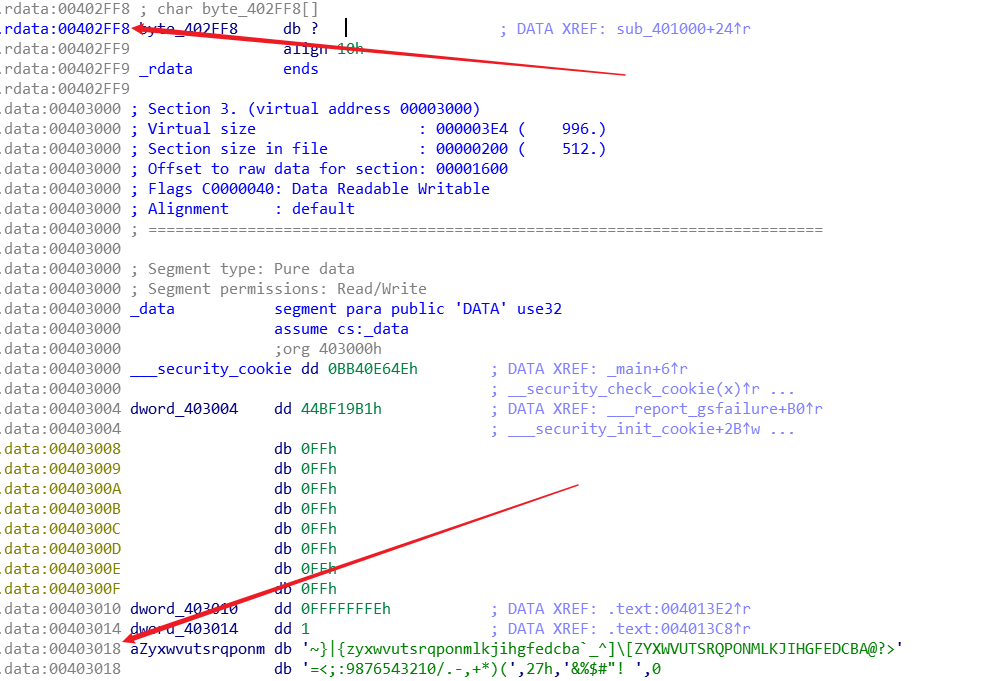
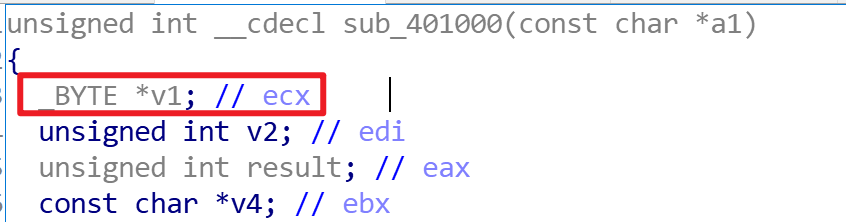
我们直接进入关键函数,要读懂程序必须读懂** * v1 = byte_402FF8[(char)v1[(_DWORD)v4]] ** 这句代码,值得注意的是不管v1,v4还是a1全都是指针形式,对于v4 = (a1 - v1),可以把式子改写为(v1 + v4) = a1,而* (v1[v4])可以理解为* (v1 + v4),所以* (v1 + v4) 指向了 a1,这样随着while循环中v1的递增就完成了对 a1 的递增。把递增得到的输入的字符作为索引,在byte_402ff8里查表转换,转换后的值存入v1。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 unsigned int __cdecl sub_401000 (const char *a1) { _BYTE *v1; unsigned int v2; unsigned int result; const char *v4; v2 = 0 ; result = strlen (a1); if ( result ) { v4 = (const char *)(a1 - v1); do { *v1 = byte_402FF8[(char )v1[(_DWORD)v4]]; ++v2; ++v1; result = strlen (a1); } while ( v2 < result ); } return result; }
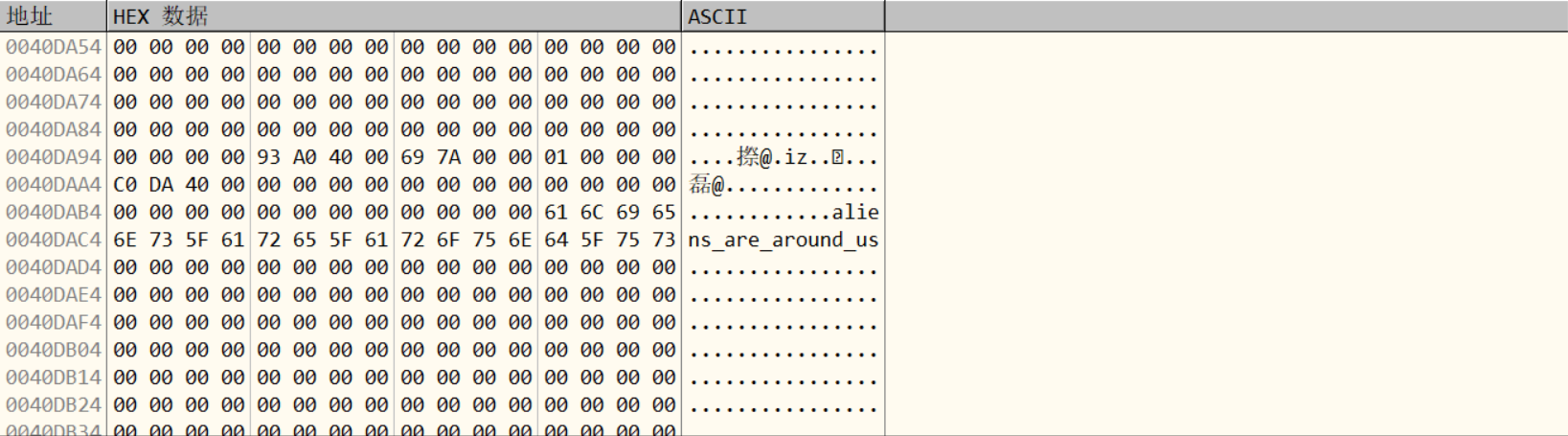
然后对于byte_402ff8 里存的字符,但是点进去发现是这样:
刚开始有点懵,因为byte_402ff8 开头的那后面跟了一堆不知道是啥的东西,但是可以发现地址没变,应该是一些声明啥啥啥的,然后尝试直接选取进行数据提取发现没问题 ,如图。
然后网上有另一种思路,ASCII码的可见字符在32以后,开始地址为0x00402ff8,加上32恰好为0x403018 ,这样就可以直接看到数据了。
这样对输入的转换就完成了,下一步就是字符串比较,这里要注意到,调用函数的时候传入的参数只有v6,但比较的时候却是和v4比较,程序看不出来端倪,我们看一下汇编,在调用函数之前,把v4的地址送如了ecx ,如下图:
然后进入被调用的函数,发现v1恰好就是ecx,而转换后的值被保存在了v1,而v1又是v4,这样转换后的值就保存在了v4,如下图:
到这里剩下的部分就简单了,把v4和给定的字符串进行判定,逆推一下就是找到字符串DDCTF{reverseME }在byte_402ff8 中所对应的位置,把位置索引转换为字符,即为输入,脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 a = [0xFF , 0xFF , 0xFF , 0xFF , 0xFF , 0xFF , 0xFF , 0xFF , 0x4E , 0xE6 , 0x40 , 0xBB , 0xB1 , 0x19 , 0xBF , 0x44 , 0xFF , 0xFF , 0xFF , 0xFF , 0xFF , 0xFF , 0xFF , 0xFF , 0xFE , 0xFF , 0xFF , 0xFF , 0x01 , 0x00 , 0x00 , 0x00 , 0x7E , 0x7D , 0x7C , 0x7B , 0x7A , 0x79 , 0x78 , 0x77 , 0x76 , 0x75 , 0x74 , 0x73 , 0x72 , 0x71 , 0x70 , 0x6F , 0x6E , 0x6D , 0x6C , 0x6B , 0x6A , 0x69 , 0x68 , 0x67 , 0x66 , 0x65 , 0x64 , 0x63 , 0x62 , 0x61 , 0x60 , 0x5F , 0x5E , 0x5D , 0x5C , 0x5B , 0x5A , 0x59 , 0x58 , 0x57 , 0x56 , 0x55 , 0x54 , 0x53 , 0x52 , 0x51 , 0x50 , 0x4F , 0x4E , 0x4D , 0x4C , 0x4B , 0x4A , 0x49 , 0x48 , 0x47 , 0x46 , 0x45 , 0x44 , 0x43 , 0x42 , 0x41 , 0x40 , 0x3F , 0x3E , 0x3D , 0x3C , 0x3B , 0x3A , 0x39 , 0x38 , 0x37 , 0x36 , 0x35 , 0x34 , 0x33 , 0x32 , 0x31 , 0x30 , 0x2F , 0x2E , 0x2D , 0x2C , 0x2B , 0x2A , 0x29 , 0x28 , 0x27 , 0x26 , 0x25 , 0x24 , 0x23 , 0x22 , 0x21 , 0x20 , 0x00 , 0x00 , 0x00 , 0x00 , 0x00 ] b = 'DDCTF{reverseME}' flag = '' for i in range (len (b)): flag += chr (a[ord (b[i])]) print (flag)
EASYHOOK emmmm怎么说呢,虽然题目是写出来了,但并没有完全理解,HOOK刚接触没多久,原理虽然是大体明白,但上到具体代码还是看的有点吃力,我觉得还是因为自己对于一些程序在装载与加载等相关方面的内容不太理解,希望能通过读程序员的自我修养得到一些解答吧。
我是采用的静态方法分析这道题的(官方给的是动态的方法解的题)。
因为题目已经说明了此题为HOOK,所以关键就是要在代码中找到与HOOK相关的代码。
程序主函数代码如下,可以看到在判断输入长度之后,直接就跳转执行了一个函数,先跟进看一下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 int __cdecl main (int argc, const char **argv, const char **envp) { int result; HANDLE v4; DWORD NumberOfBytesWritten; char input_; sub_401370((int )aPleaseInputFla); scanf (a31s, &input_); if ( strlen (&input_) == 19 ) { sub_401220(); v4 = CreateFileA(FileName, 0x40000000 u, 0 , 0 , 2u , 0x80 u, 0 ); WriteFile(v4, &input_, 0x13 u, &NumberOfBytesWritten, 0 ); sub_401240(&input_, &NumberOfBytesWritten); if ( NumberOfBytesWritten == 1 ) sub_401370((int )aRightFlagIsYou); else sub_401370((int )aWrong); system(aPause); result = 0 ; } else { sub_401370((int )aWrong); system(aPause); result = 0 ; } return result; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int sub_401220 () { HMODULE v0; DWORD v2; v2 = GetCurrentProcessId(); hProcess = OpenProcess(0x1F0FFF u, 0 , v2); v0 = LoadLibraryA(LibFileName); hook_id = (int )GetProcAddress(v0, ProcName); lpAddress = (LPVOID)hook_id; if ( !hook_id ) return sub_401370((int )&unk_40A044); hool_re = *(_DWORD *)lpAddress; *((_BYTE *)&hool_re + 4 ) = *((_BYTE *)lpAddress + 4 ); byte_40C9BC = -23 ; dword_40C9BD = (char *)sub_401080 - (char *)lpAddress - 5 ; return sub_4010D0(); }
如果没搞错这应该是一个Address Hook,也就是说对函数的地址进行了修改。但实在学艺不精,我没看懂关键代码。只能大概判断出哪里是关键,但是不知道到底干了什么。跟进函数sub_401080。
1 2 3 4 5 6 7 8 9 10 11 int __stdcall sub_401080 (HANDLE hFile, LPCVOID lpBuffer, DWORD nNumberOfBytesToWrite, LPDWORD lpNumberOfBytesWritten, LPOVERLAPPED lpOverlapped) { signed int v5; v5 = sub_401000((int )lpBuffer, nNumberOfBytesToWrite); sub_401140(); WriteFile(hFile, lpBuffer, nNumberOfBytesToWrite, lpNumberOfBytesWritten, lpOverlapped); if ( v5 ) *lpNumberOfBytesWritten = 1 ; return 0 ; }
再跟进sub_401000。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 signed int __cdecl sub_401000 (int input, signed int num) { char v2; char v3; char v4; int v5; v2 = 0 ; if ( num > 0 ) { do { if ( v2 == 18 ) { *(_BYTE *)(input + 18 ) ^= 0x13 u; } else { if ( v2 % 2 ) v3 = *(_BYTE *)(v2 + input) - v2; else v3 = *(_BYTE *)(v2 + input + 2 ); *(_BYTE *)(v2 + input) = v2 ^ v3; } ++v2; } while ( v2 < num ); } v4 = 0 ; if ( num <= 0 ) return 1 ; v5 = 0 ; while ( after_change[v5] == *(_BYTE *)(v5 + input) ) { v5 = ++v4; if ( v4 >= num ) return 1 ; } return 0 ; }
一通瞎β操作来到关键函数,直接写解密脚本,捞的不谈。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 a = [0x61 , 0x6A , 0x79 , 0x67 , 0x6B , 0x46 , 0x6D , 0x2E , 0x7F , 0x5F , 0x7E , 0x2D , 0x53 , 0x56 , 0x7B , 0x38 , 0x6D , 0x4C , 0x6E ] fl = 19 * ' ' flag = list (fl) v2 = 18 while (v2): if (v2 == 18 ): flag[18 ] = chr (a[18 ] ^ 0x13 ) elif (v2 % 2 ): flag[v2] = chr ((a[v2] ^ v2) + v2) else : flag[v2 + 2 ] = chr (v2 ^ a[v2]) v2 = v2 - 1 print ("" .join(flag))
得到的flag格式有点问题,改一下就OK了,至于为什么,算了,不关心了,就这样吧。
signin 发现直接是个RSA算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 __int64 __fastcall main (__int64 a1, char **a2, char **a3) char n; char e; char m; char c; char _input; char v9; unsigned __int64 v10; v10 = __readfsqword(0x28 u); puts ("[sign in]" ); printf ("[input your flag]: " , a2); __isoc99_scanf("%99s" , &_input); sub_96A (&_input, (__int64)&v9); __gmpz_init_set_str((__int64)&c, (__int64)"ad939ff59f6e70bcbfad406f2494993757eee98b91bc244184a377520d06fc35" , 16LL ); __gmpz_init_set_str((__int64)&m, (__int64)&v9, 16LL ); __gmpz_init_set_str( (__int64)&n, (__int64)"103461035900816914121390101299049044413950405173712170434161686539878160984549" , 10LL ); __gmpz_init_set_str((__int64)&e, (__int64)"65537" , 10LL ); __gmpz_powm((__int64)&m, (__int64)&m, (__int64)&e, (__int64)&n); if ( (unsigned int )__gmpz_cmp((__int64)&m, (__int64)&c) ) puts ("GG!" ); else puts ("TTTTTTTTTTql!" ); return 0LL ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import gmpy2n = 103461035900816914121390101299049044413950405173712170434161686539878160984549 p = 366669102002966856876605669837014229419 q = 282164587459512124844245113950593348271 l = (p - 1 ) * (q - 1 ) e = 65537 d = int (gmpy2.invert(e, l)) c = 0xad939ff59f6e70bcbfad406f2494993757eee98b91bc244184a377520d06fc35 m = pow (c, d, n) flag0 = hex (m)[2 :] print (flag0)flag1 = bytes .fromhex(flag0) print (flag1)flag = str (flag1, 'utf-8' ) print (flag)
suctf{Pwn_@_hundred_years}
梅津美治郎 首先Level1直接是个字符串比较,很好通过,然后就没有什么显而易见的线索了,分析一下代码。
原代码里定义了非常多的变量,咋一看好像都是些没啥用的字符串,跟进sub_401500()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int __cdecl sub_401500 (signed int a1) { int result; _BYTE *i; if ( a1 <= 9 ) return sub_401500(a1 + 1 ); for ( i = (_BYTE *)dword_40AD94; ; ++i ) { result = dword_40ADA0; if ( (unsigned int )i >= dword_40ADA0 ) break ; *i ^= 1u ; } return result; }
可以看到函数对定义的那部分变量进行了 ^ 1的处理,然后发现其实就是弹窗里提示的字符。
继续分析,v3,v4,v5看着有点像hook来着。
继续分析,来到sub_40157F()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void __cdecl __noreturn sub_40157F (int a1) { char v1; int v2; v2 = *(_DWORD *)(*(_DWORD *)(a1 + 4 ) + 184 ); if ( v2 == dword_40ADA8 + 6 ) { scanf ("%20s" , &v1); if ( !sub_401547(&v1, (_BYTE *)dword_40AD98) ) puts (dword_40ADA4); } ExitProcess(0 ); }
继续跟进sub_401547(),找出使if判断成功的条件。
1 2 3 4 5 6 7 8 9 10 11 signed int __cdecl sub_401547 (_BYTE *a1, _BYTE *a2) { while ( *a2 != 2 ) { if ( *a1 != (*a2 ^ 2 ) ) return 1 ; ++a1; ++a2; } return 0 ; }
v1是我们的输入,那关键就是v2了,对dword_40AD98进行交叉引用,发现是定义的变量&v28
1 2 3 4 5 a = 't0oog3mf' flag = '' for i in a: flag += chr (ord (i) ^ 1 ^ 2 ) print (flag)
继续分析进入sub_4015EA(0)
1 2 3 4 5 6 7 8 9 int __cdecl sub_4015EA (signed int a1) { if ( a1 <= 9 ) return sub_4015EA(a1 + 1 ); puts (dword_40AD90); dword_40ADA8 = 0x401619 ; __debugbreak(); return 0 ; }
程序对dword_40ADA8 进行了修改,对其进行交叉引用,发现来到了sub_40157F(),那这应该就是程序第二部分了。过关密码应该就是我们上面破译的w3lld0ne。
最后的flag就是把两个密码用‘_’ 链接起来就可以了,至于为什么我没想明白。
另外网上说可以动调直接在Level1后来到level2,我没试出来,没想明白。
flag{r0b0RUlez!_w3lld0ne}
easyRE 很久没在buuoj上刷过题了,一上来就遇到个有趣的。
本题主逻辑可以说是相当签到了,但是都是虚晃一枪,解题关键在于.fini_array段,有关博客
大多数可执行文件是通过链接 libc 来进行编译的,因此 gcc 会将 glibc 初始化代码放入编译好的可执行文件和共享库中。 .init_array和 .fini_array 节(早期版本被称为 .ctors和 .dtors )中存放了指向初始化代码和终止代码的函数指针。 .init_array 函数指针会在 main() 函数调用之前触发。这就意味着,可以通过重写某个指向正确地址的指针来将控制流指向病毒或者寄生代码。 .fini_array 函数指针在 main() 函数执行完之后才被触发,在某些场景下这一点会非常有用。例如,特定的堆溢出漏洞(如曾经的 Once upon a free() )会允许攻击者在任意位置写4个字节,攻击者通常会使用一个指向 shellcode 地址的函数指针来重写.fini_array 函数指针。对于大多数病毒或者恶意软件作者来说, .init_array 函数指针是最常被攻击的目标,因为它通常可以使得寄生代码在程序的其他部分执行之前就能够先运行。
Youngter-drive 这个也有点意思,大概就是创建了两个线程,共用了一个临界资源,轮流使用这样子。