

比赛中的几个题。
网鼎杯2020
signal
其他的没啥说的,摸透逻辑了就知道怎么做了,但是感觉这个题能写脚本我觉得完全是个意外,如果控制位和数据位太多一样的那结果就有点多了,写脚本难度感觉要猛增。
直接看关键函数逻辑吧。
1 | int __cdecl vm_operad(int *given, int num) |
这里可以看到case 3的时候出现了**LOBYTE(given[n + 1])**,测试一下。
1 |
|
OK上脚本,其实除了对于case 1的判断,其他的有点多余了,因为并没有出现特列。
1 | g = [10,4,16,8,3,5,1,4,32,8,5,3,1,3,2,8,11,1,12,8,4,4,1,5,3,8, |
这里额外插一嘴,写脚本的时候,对于unknum += 1这句,我最开始写的是 ++unknum,然后一直不对,后来查了一下,python解释器会把++a/–a解释成 +(+a)/-(-a) 所以相当于没变
SCTF2020
get_up
看题目就知道是个签到题了,俗话说的好啊,一杯茶,一包烟,一道签到签一天。
一顿瞎β操作后拖进IDA,找到主函数
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
继续跟进sub_4027000()
1 | int sub_402700() |
注意到if语句有个对输入的操作函数dec_md5(手动改的名字),可以看到一些熟悉的操作,轮次,右移32位,加密后32位长度,那我说这是个md5应该没人反对,在线破解出输入为“sycsyc”。
1 | Size = strlen(Str); |
下面进入sub_402610(),发现是个不复杂的异或操作
1 | void __cdecl sub_402610(int a1, char *Str) |
那下面运用idapython来对其进行处理,代码如下,完成之后选中.reioc段数据,按u取消数据类型定义,再按p使其转成代码。
1 | dst = 0x405000 |
转化完成后:

再f5就可以直接反编译了,主要函数如下:
1 | void sub_4027F0() |
再次用到idapython
1 | dst = 0x404000 |
这里就遇到一个大坑了,转化前是这样的:
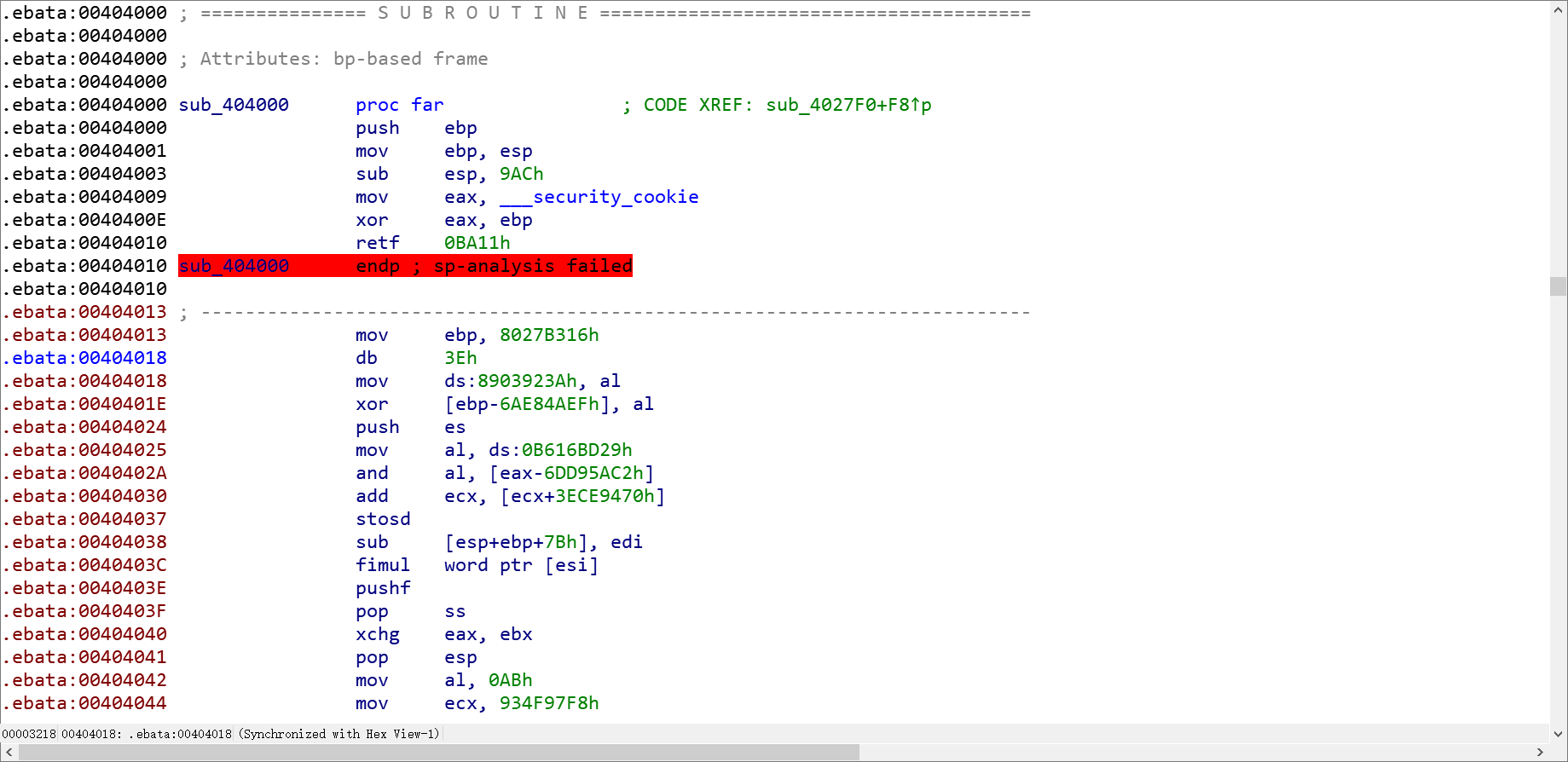
转化后是这样的:
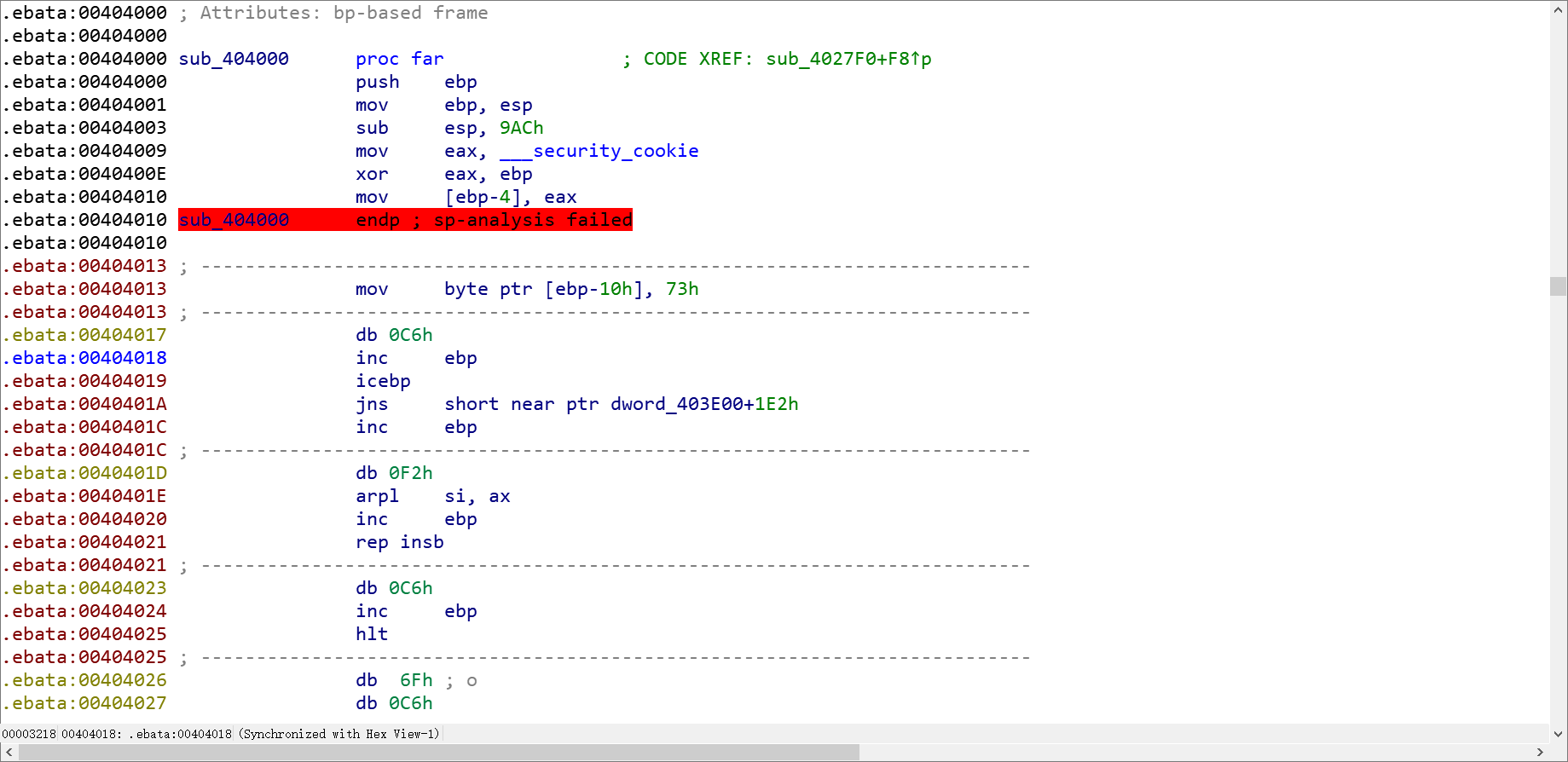
因为可以看到在我们进行U和P之前,这里已经存在了一段汇编代码,然后我们进行异或的起点又是第16位,然后我就想当然觉得只要把后面的数据进行U和P就可以了,然后再解决sp analysis failed的错误就行,但是这样反汇编出来的代码特别特别难看,数据定义识别不准确,偏偏网上其他大佬的题解还都说是要分析sp analysis failed的,我真是信了他妈的邪了。
这里我们直接选中全部.ebata段,取消定义然后再转成代码就可以。转化完成后:
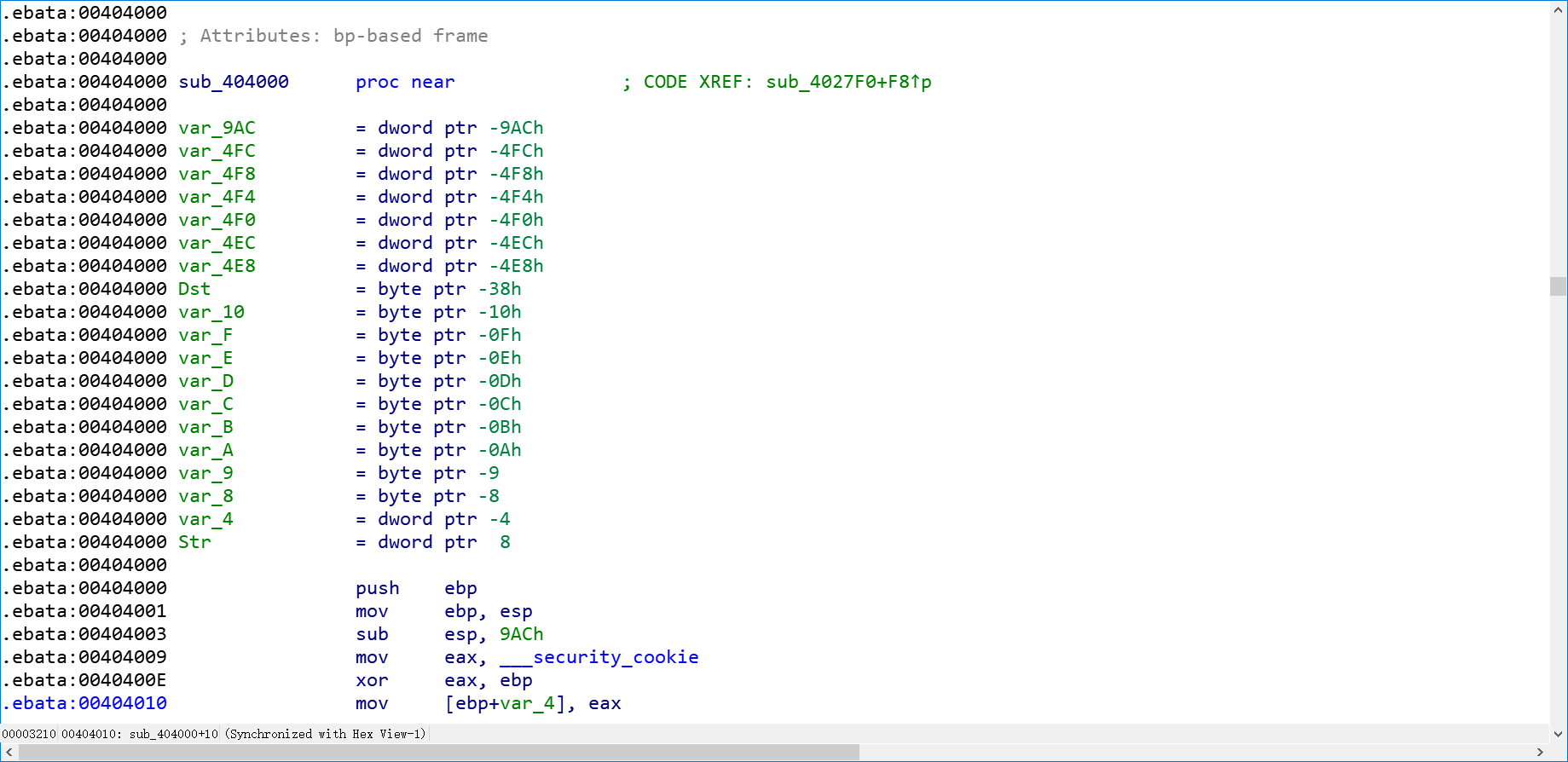
直接f5,舒服
1 | int __cdecl sub_404000(char *Str) |
然后再就是一些代码分析了,可以爆破出flag来,直接上最后的脚本:
1 | #include<bits/stdc++.h> |
SCTF{zzz~(|3[___]_rc4_5o_e4sy}
signin
好的废话 不多说我们直接拖IDA,然后就看到顶部的红色警告,这一度让我怀疑程序是不是加壳了,然后一查才知道是pyhton打包过的,那说是加壳也不过分。
这类文件的特点就是,前面和后面多个“_”,如下图

那现在开始反编译,以下两种方法都可以
archive_viewer.py
使用archive_viewer.py反编译文件,另外pyc文件有个magic head,然后pyinstaller生成exe的时候会把Pyc的magic部分去掉,所以反编译之后需要补齐,一个小技巧是可以从struct文件的前16个字节获取。
python archive_viewer.py signin.exe
- U: go Up one level
- O
: open embedded archive name - X
: extract name - Q: quit
1 | #----------------------------------------------------------------------------- |
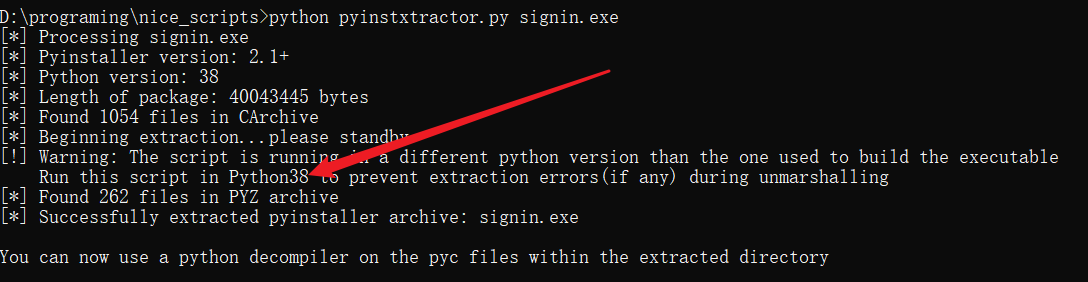
pyinstxtractor.py
python pyinstxtractor.py signin.exe
打包后回生成个文件夹,里面的main和struct文件就是我们要的
推荐是用这个的,用这个可以看到版本信息等其他信息,很方便。
比如说本题中uncompyle6就得用pyhton3.8的环境
1 | #!/usr/bin/python |
现在我们已经得到的.pyc文件了,下面我们把pyc转成py就可以了,但是很尴尬的是必须是3.8的环境,然后各个宣称支持3.8的在线破解网站也纷纷失败,没办法只得虚拟机下搞了个3.8,真的恼火
uncompyle6 main.pyc > main.py
打开py,开始代码分析
1 | # uncompyle6 version 3.7.3 |
大概就是调用tmp.dll的enc函数对传进来的username和password进行加密,password加密后送入pwd_safe。最后用户名为“SCTFer”,密码为b64decode(b’PLHCu+fujfZmMOMLGHCyWWOq5H5HDN2R5nHnlV30Q0EA’)
然后我就陷入了tmp.dll到底在哪的难题,一通百度谷歌猛如虎,然后一查题解在运行的时候会在同目录下生成一个tmp.dll程序关闭就没了。
拖入IDA,找到enc函数,开始分析
1 | if ( v10 <= len ) |
1 | for ( j = 0; j < 64; ++j ) |
然后就是写脚本了,然后才发现我的python水平是真的烂,一脸懵逼不知道怎么写,直接放网上大佬的脚本。
1 | from base64 import * |
SCTF{We1c0m3_To_Sctf_2020_re_!!}
这个题算不上很完整的复现了,有个别细节没搞懂,也有点懒得搞了,先这样吧。
2020国赛
z3
其他还好就是复制粘贴有点累人
1 | from z3 import * |
hyperthreading
比赛的时候愣是没做出来,比完之后的半夜突然懂了,原来是数据没转成函数…….
之前在XCTF有接触到过一道HOOK的题目,也不能说对HOOK完全不理解,大概就是构造一个长得一样的函数然后通过手段替换掉(不知道这样说对不对),所以关键就是找到这个函数了。
跟HOOK相关的也就那么几行,就是一个一个点也能试出来。
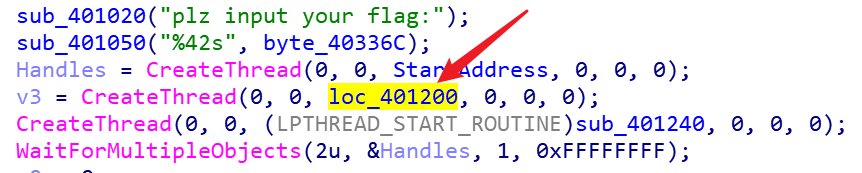
过去之后这样,我也没感觉有啥不对,push ebp. move ebp, esp. 感觉是个很规范的开头,然后就没有然后了。
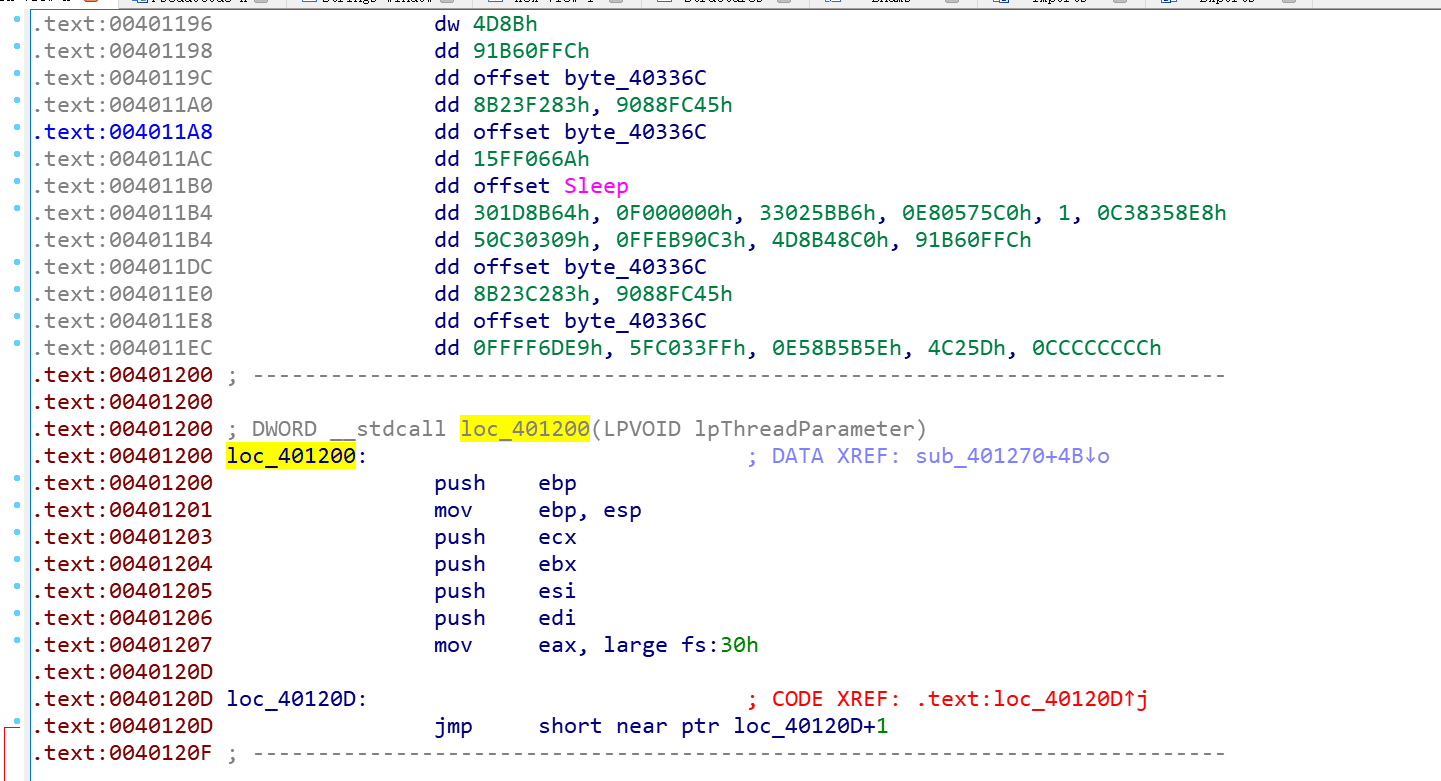
时间就来到今晚,再次看到上面那一大段数据,菜鸡心里突然感到一阵不安,然后一顿u+p,好家伙,果然是段程序。
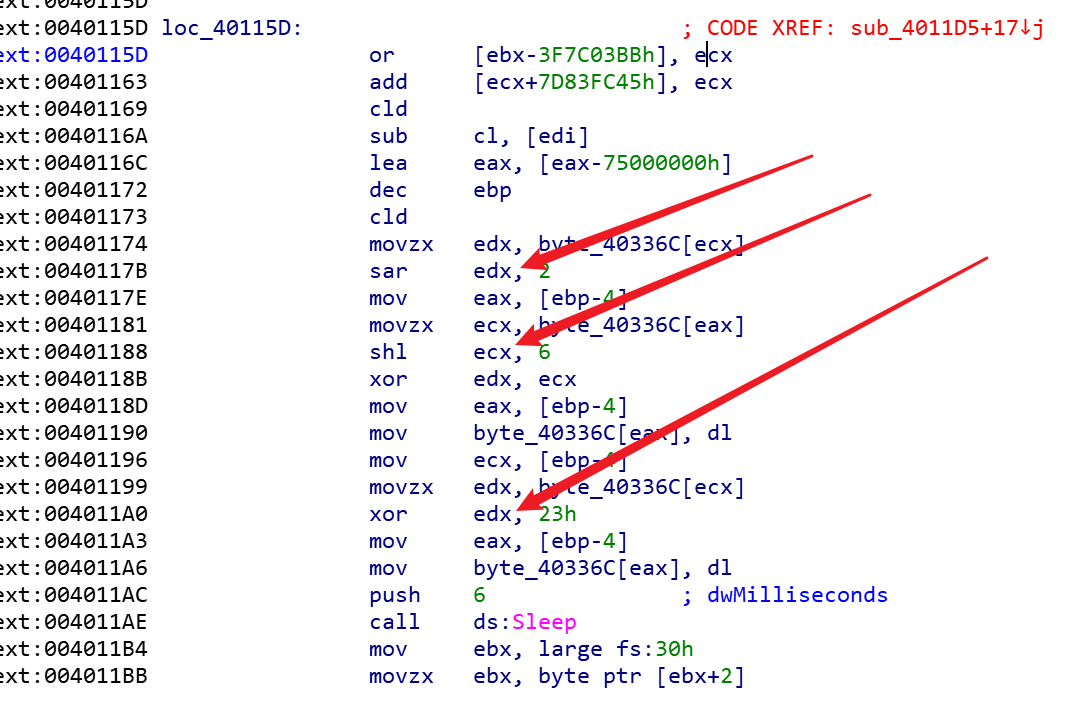
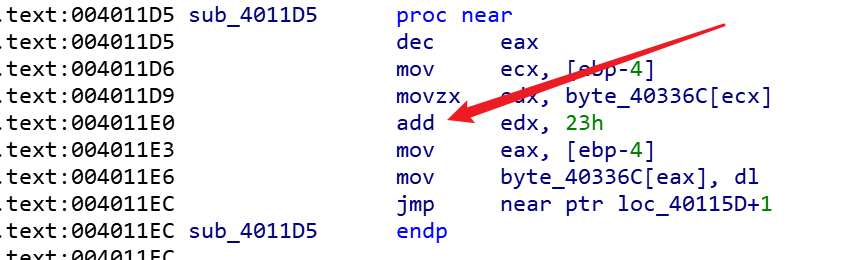
我们需要关注的就是主函数中参与最终比较的byte_40336C。这段代码是可以反汇编的,但是下面的那个再加上0x23的那段函数并不在反汇编出来的函数之中,因为毕竟是我们u+P出来的,有点错误可以接受,猜测应该是jmp那里出了问题没有反编译完整,所以好的做法是根据汇编代码中byte_40336C的高亮提示逐步排查一下。
脚本:
1 | a = [ 0xDD, 0x5B, 0x9E, 0x1D, 0x20, 0x9E, 0x90, 0x91, 0x90, 0x90, |
bd
本来啥也不懂,然后群里学长指路说是wiener’s attack,那知道攻击方法了就没啥了
记录一下网上大佬的脚本:
1 | import gmpy2 |
今天发这篇博客纯属意外,白天和老妈吵了一架,晚上听着窗外夜雨实在难以入眠,所以干脆先记录一下,之后几天还有其他的比赛,可能没心思再回顾了,睡觉了,世界晚安。